- [AI] AWS Generative AI 기초 교육 - Discriminative AI, GenAI, LLM, 멀티모달, FMs, 파인튜닝2024년 01월 22일 18시 42분 38초에 업로드 된 글입니다.작성자: 주사위 clice반응형

지난 시간에 AI/ML머신러닝/DL딥러닝에 대해 알아보았다
(지난 글 보기: https://clice.tistory.com/entry/AI-AWS에서-배운-Generative-AI-기초-교육-AIML머신러닝DL딥러닝 )[AI] AWS에서 배운 Generative AI 기초 교육 - AI/ML머신러닝/DL딥러닝
지난 12월 AWS Generative AI Basic 교육을 알게 되었다 요즘 AI 분야는 하루가 다르게 발전되고 있다, 이에 AI를 이용한 서비스를 개발할 기회는 점점 많아지고 있다. 따라서 AI에 대한 기초를 다지고자
clice.tistory.com
이어서 Generative AI에 대해 자세히 알아보자
Generative AI
발전과정
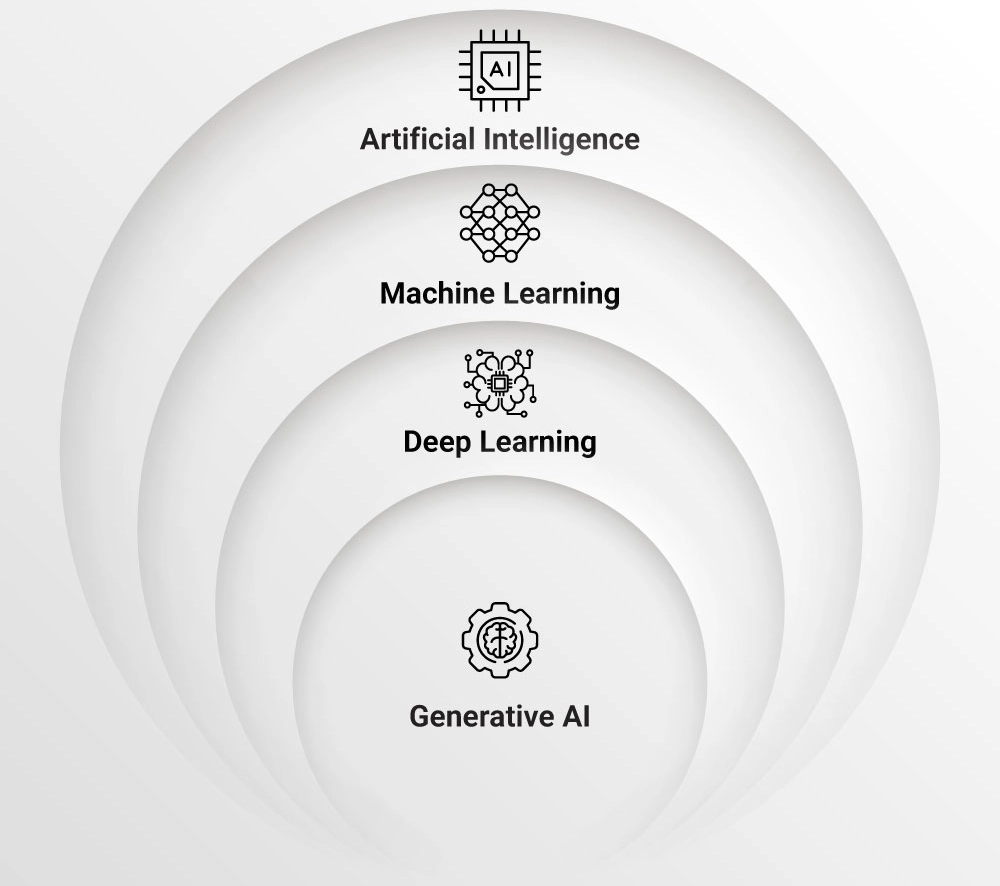
출처: Synoptek
AI는 인간의 지적 능력을 모방하는 기술로 시작하여, ML은 데이터 학습을 통해 모델을 개발하는 방식으로 발전했다
이후 DL은 인공 신경망을 활용하여 더 복잡하고 라벨링 없이도 추상적인 패턴을 학습하며
마침내 Gen AI는 인간과 유사한 추론과 창의성을 갖춘 다양한 지능을 포괄하는 발전 단계로 나아가고 있다
Discriminative AI VS Generative AI
Generative AI와 Discriminative AI에 대해 알아보자
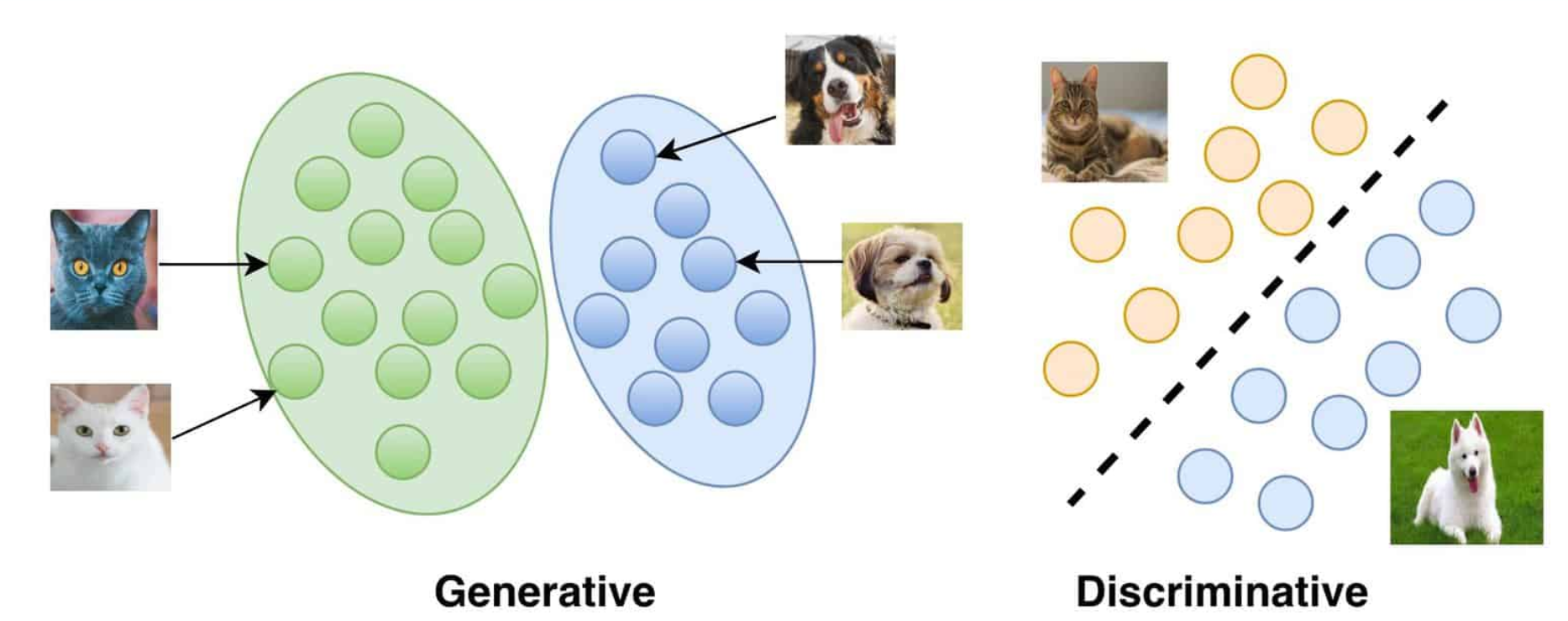
출처: https://vitalflux.com/generative-vs-discriminative-models-examples/
Discriminative AI
고양이 사진 1만장, 강아지 사진 1만장을 보고
동물 사진을 줬을때, 이것이 강아지인지 고양이인지 규칙에 따라 분류한다- 정의: 주어진 입력 데이터를 분류하거나 예측하는 데 중점을 둔 AI 유형이다
- 작업: 분류, 회귀, 판별 등과 같은 명시적인 작업에 활용된다
- 활용 분야: 얼굴 인식, 스팸 필터링, 객체 감지 등의 분야에 활용된다
- 특징: 주로 지도 학습 (Supervised Learning)을 기반으로 하며, 라벨링된 데이터를 사용하여 모델을 훈련한다
Generative AI:
고양이 사진 1만장을 학습한 뒤, 스스로 고양이 이미지를 만들어낸다(생성)- 정의: 주어진 데이터의 분포를 학습하고, 그 분포를 기반으로 새로운 데이터를 생성하는 데 중점을 둔 AI 유형이다
- 작업: 문장, 이미지, 음성 등의 데이터를 생성하는 데 사용된다
- 활용 분야: 텍스트 생성, 이미지 생성, 음악 작곡 등 다양한 창의적 작업에 적용된다
이러한 특성을 통해 Discriminative AI는 주로 명시적이고 특정한 작업에 사용되는 반면, Generative AI는 창의적이고 다양성이 필요한 작업에 활용됩니다.
Large Language Models & Foundation Models (FMs)
LLM 이란?
LLM은 대량의 텍스트 데이터(말뭉치 데이터)로 학습된 대규모 인공 신경망을 의미한다. 이는 주로 자연어 처리(NLP) 작업에 활용되며, 최근에는 transformer attention mechanism을 기반으로 하는 모델이 많이 사용되고 있다
Transformer Attention Mechanism
Google에서 발표한 "Attention is All You Need" 논문에서 소개된 transformer 모델이 LLM에 많이 사용된다
이는 self-attention 메커니즘을 통해 문장의 장기 의존성을 처리하고, 많은 양의 데이터를 효과적으로 학습할 수 있다.
참고 논문 링크: [Attention is All You Need](https://research.google/pubs/pub46201/)
작동 방식
LLM은 입력된 텍스트에 대해 이전과 다르게 단순한 라벨이 아닌, 맥락을 고려하여 다양한 작업을 수행할 수 있다.
"고양이는 다리의 개수가 ~"라는 문장을 예로 들면, <4개이다>라는 뒷 부분을 예측하고 생성함으로써 문장의 맥락을 이해하고 의미 있는 문장을 생성한다
LLM (text-to-text) vs. Multimodal
LLM (text-to-text)
적용 분야: 여러 어플리케이션에 적용될 수 있게 심플한 자연어 질의에 대한 답변 문장을 생성한다.
사용 예시
Text summarization
Information extraction
Question Answering
Text Classification
Conversation
Code Generation
Reasoning
특징: 텍스트 입력에 대한 텍스트 출력을 생성하며, 다양한 NLP 작업에 적용 가능하다
Multimodal
적용 분야: 자연어 질의 뿐 아니라 이미지, 오디오, 영상 정보를 입력으로 받고 출력으로 생성한다. 입력과 출력의 모드가 다양하다
여러 모드의 입력과 출력을 처리하며, 텍스트 이외의 다양한 미디어 정보를 다룰 수 있다
사용 예시:
Text-to-Image
Image-to-Image
Inpainting
Masking
Upscaling
이러한 LLM과 Multimodal은 각각의 특성에 따라 다양한 응용 분야에서 활용되고 있다. LLM은 주로 텍스트 관련 작업에 중점을 두며, Multimodal은 텍스트 이외의 다양한 입력과 출력을 다루는 데 적합하다.
Foundation Models (FMs)
Foundation Models은 방대한 양의 일반 도메인 데이터(인터넷에 있는 자료들)로 학습된 기반 모델을 나타낸다. 이러한 모델은 다양한 사용 사례에 맞게 구현되거나 사용자 정의가 가능한 특징을 갖추고 있다.
프롬프트 엔지니어링
Zero-shot prompting
모델이 힌트 없이도 라벨링된 데이터 없이 일반화할 수 있게 하는 방법이다. 예를 들어, "이거는 뭐니?"라는 질문에 모델이 적절한 답을 생성할 수 있다.
Few-shot prompting
힌트가 포함된 프롬프트를 사용하여 모델이 라벨링된 데이터 없이도 일반화할 수 있게 하는 방법이다. 예를 들어, "ㅇㅇㅇㅇ는 어떤 것이야~ 그럼 이거는 뭐니?"라는 프롬프트에 모델이 적절한 답을 생성할 수 있다.
한계
지식 단절 (knowledge cutoff)

특정 시점까지의 데이터만 학습할 수 있어서 그 이후의 정보는 반영되지 않는다. chatGPT에게 현재 미국 대통령 정보를 물어보면, 모른다고 답변하는건 이 때문이다
환각 (Hallucination)
생성 모델의 한계로, 거짓말이나 잘못된 정보를 생성할 수 있다.
한계 극복법
Fine-tuning 파인튜닝
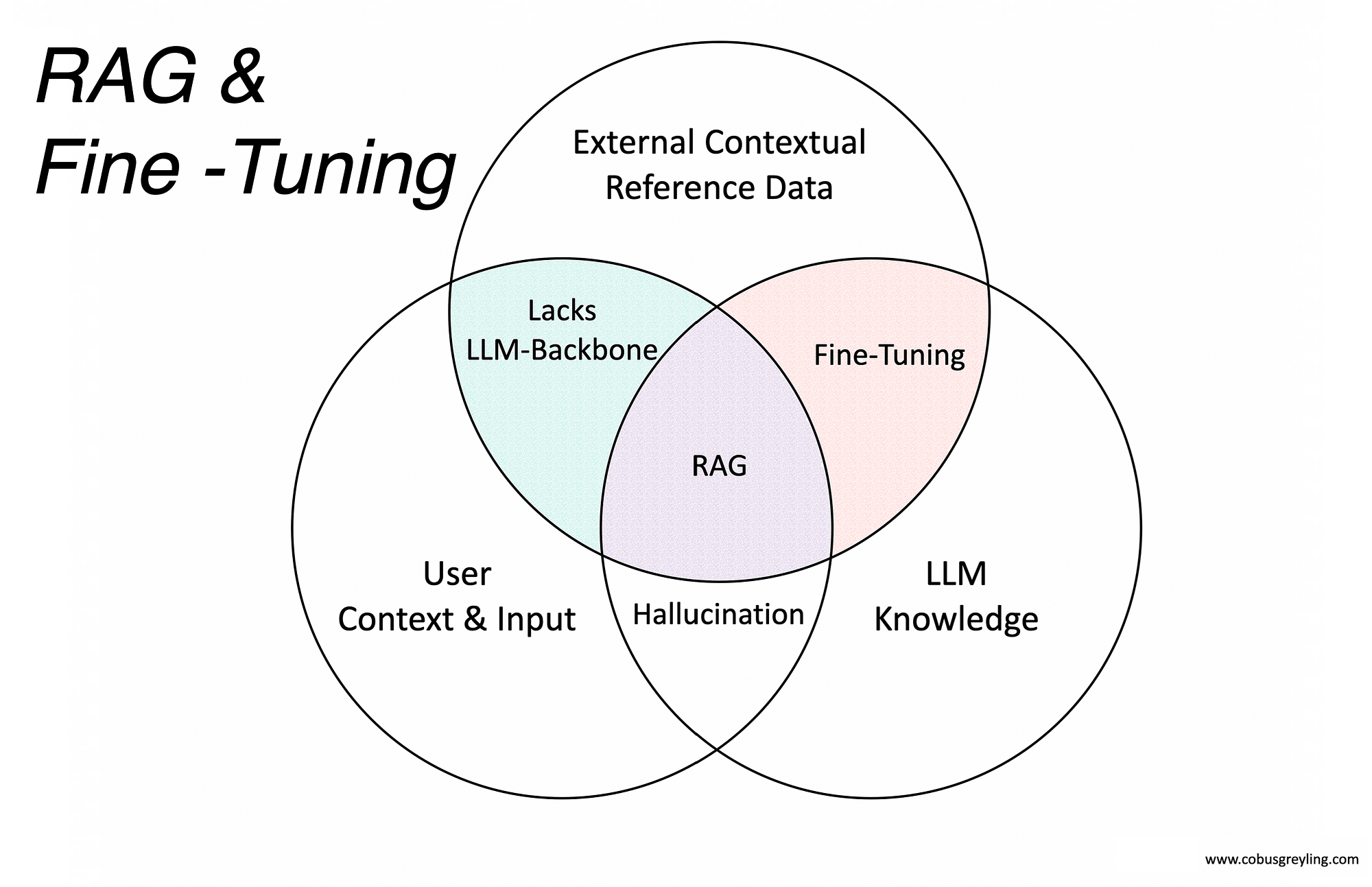
https://cobusgreyling.medium.com/rag-fine-tuning-e541512e9601 기반 모델을 사용하여 도메인 데이터를 추가 학습하여 한정된 도메인에 대한 성능을 향상시키는 방법이다.
Retrieval Augmented Generation (RAG)
검색 레이어를 도입하여 더 나은 이해와 답변을 가능하게 하는 방법으로, 추가적인 컨텍스트를 효과적으로 찾을 수 있도록 한다
PEFT (Parameter-Efficient Fine Tuning)
사전 학습된 LLM의 대부분의 파라미터를 비활성화하고, 필요한 일부 파라미터만을 미세 조정하여 저장 공간과 계산 능력을 효과적으로 관리하는 방법입니다. 작은 데이터 세트에서 효과적으로 활용된다.
Image Generation: Diffusion Models
디퓨전 모델은 이미지를 생성하는 확률적인 방법으로, 이미지 생성 과정을 확률적인 확산(diffusion) 단계로 나누어 처리한다.
Forward Diffusion (순방향 확산)
생성하고자 하는 이미지를 초기 노이즈로 시작하여 확산 단계를 거쳐 실제 이미지에 가까워지도록 진행한다
노이즈에서부터 시작하여 시간이 지남에 따라 이미지의 픽셀값을 조금씩 조정하여 디퓨젼 과정을 거친다
무작위한 노이즈로부터 시작하여, 시간이 흐름에 따라 점진적으로 정교한 이미지를 형성하도록 한다
Reverse Diffusion (역방향 확산)
실제 이미지를 노이즈로 변환하는 과정으로, 순방향 확산의 역순으로 진행된다
이미지를 초기 노이즈로 역변환하며, 확산된 이미지를 원래의 초기 노이즈로 복원한다
생성된 이미지를 다시 초기 노이즈로 복원함으로써 이미지를 재형성하고, 원래의 생성된 이미지와 초기 노이즈 간의 관계를 학습한다
반응형'CS > AI' 카테고리의 다른 글
[AI] AWS에서 배운 Generative AI 기초 교육 - AI/ML머신러닝/DL딥러닝 (0) 2024.01.21 이전글이 없습니다.댓글